GAT implementation¶
Graphic Attention Network
Official resources from Blog.
[1]:
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
Structure¶
[2]:
class GATLayer(nn.Module):
"""
Simple PyTorch Implementation of the Graph Attention layer.
"""
def __init__(self):
super(GATLayer, self).__init__()
def forward(self, input, adj):
print("")
Let’s start from the forward method¶
Linear Transformation¶
\[\bar{h'}_i = \textbf{W}\cdot \bar{h}_i\]
with \(\textbf{W}\in\mathbb R^{F'\times F}\) and \(\bar{h}_i\in\mathbb R^{F}\).
\[\bar{h'}_i \in \mathbb{R}^{F'}\]
[3]:
in_features = 5
out_features = 2
nb_nodes = 3
W = nn.Parameter(torch.zeros(size=(in_features, out_features))) #xavier paramiter inizializator
nn.init.xavier_uniform_(W.data, gain=1.414)
input = torch.rand(nb_nodes,in_features)
# linear transformation
h = torch.mm(input, W)
N = h.size()[0]
print(h.shape)
torch.Size([3, 2])
[4]:
input.size()
[4]:
torch.Size([3, 5])
Attention Mechanism¶
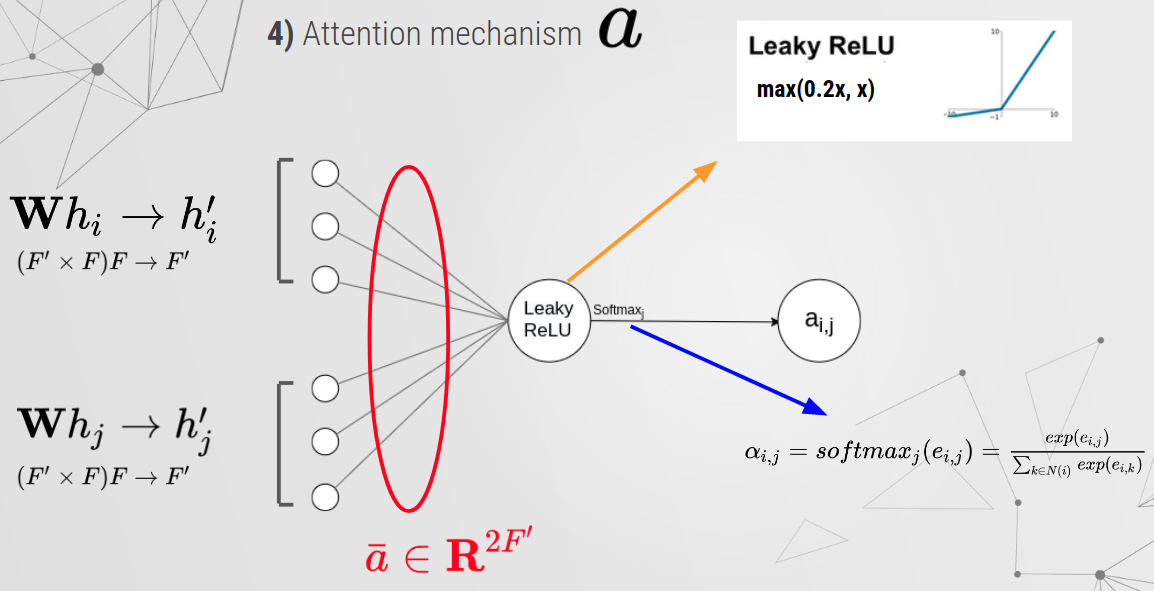
[5]:
a = nn.Parameter(torch.zeros(size=(2*out_features, 1))) #xavier paramiter inizializator
nn.init.xavier_uniform_(a.data, gain=1.414)
print(a.shape)
leakyrelu = nn.LeakyReLU(0.2) # LeakyReLU
torch.Size([4, 1])
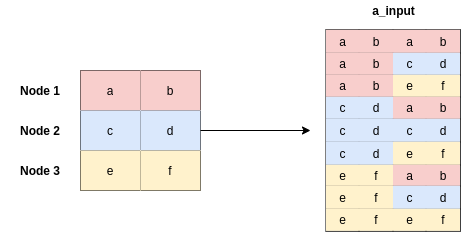
[6]:
a_input = torch.cat([h.repeat(1, N).view(N * N, -1), h.repeat(N, 1)], dim=1).view(N, -1, 2 * out_features)
[7]:
a_input.shape
[7]:
torch.Size([3, 3, 4])
[8]:
e = leakyrelu(torch.matmul(a_input, a).squeeze(2))
Row \(i\) of e is the coeffcients in for row \(i\). Thus, we will get a \(N*N\) matrix, where \(N\) is the number of nodes.
[9]:
print(a_input.shape,a.shape)
print("")
print(torch.matmul(a_input,a).shape)
print("")
print(torch.matmul(a_input,a).squeeze(2).shape)
torch.Size([3, 3, 4]) torch.Size([4, 1])
torch.Size([3, 3, 1])
torch.Size([3, 3])
Masked Attention¶
Since \(e_{ij}\) are computed for all pairs of in this \(3\times3\) matrix, we need to mask out those coefficients for those not in the neighborhood of each node, i.e., only keep coefficients that correspond to edges in graph.
[10]:
# Masked Attention
adj = torch.randint(2, (3, 3))
zero_vec = -9e15*torch.ones_like(e)
print(zero_vec.shape)
torch.Size([3, 3])
We use \(-9e15\) as the zero entries, because we will perform exponential operation on \(e_{i,j}\) later and a small enough negative number will produce zero on exponent.
[11]:
attention = torch.where(adj > 0, e, zero_vec)
print(adj,"\n",e,"\n",zero_vec)
attention
tensor([[1, 1, 1],
[1, 0, 1],
[1, 0, 0]])
tensor([[-0.3351, -0.2840, -0.3298],
[-0.2346, -0.1835, -0.2293],
[-0.2771, -0.2260, -0.2718]], grad_fn=<LeakyReluBackward0>)
tensor([[-9.0000e+15, -9.0000e+15, -9.0000e+15],
[-9.0000e+15, -9.0000e+15, -9.0000e+15],
[-9.0000e+15, -9.0000e+15, -9.0000e+15]])
[11]:
tensor([[-3.3511e-01, -2.8395e-01, -3.2975e-01],
[-2.3463e-01, -9.0000e+15, -2.2928e-01],
[-2.7714e-01, -9.0000e+15, -9.0000e+15]], grad_fn=<SWhereBackward0>)
[12]:
attention = F.softmax(attention, dim=1) # softmax over columns(each row vector)
h_prime = torch.matmul(attention, h)
[13]:
attention
[13]:
tensor([[0.3270, 0.3442, 0.3288],
[0.4987, 0.0000, 0.5013],
[1.0000, 0.0000, 0.0000]], grad_fn=<SoftmaxBackward0>)
[14]:
h_prime
[14]:
tensor([[-0.5785, 0.6305],
[-0.7469, 0.5793],
[-0.9134, 0.4681]], grad_fn=<MmBackward0>)
h_prime vs h¶
[15]:
print(h_prime,"\n",h)
tensor([[-0.5785, 0.6305],
[-0.7469, 0.5793],
[-0.9134, 0.4681]], grad_fn=<MmBackward0>)
tensor([[-0.9134, 0.4681],
[-0.2576, 0.7279],
[-0.5813, 0.6900]], grad_fn=<MmBackward0>)
Build the layer¶
[16]:
class GATLayer(nn.Module):
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
super(GATLayer, self).__init__()
'''
TODO
'''
def forward(self, input, adj):
# Linear Transformation
h = torch.mm(input, self.W) # matrix multiplication
N = h.size()[0]
# Attention Mechanism
a_input = torch.cat([h.repeat(1, N).view(N * N, -1), h.repeat(N, 1)], dim=1).view(N, -1, 2 * self.out_features)
e = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(2))
# Masked Attention
zero_vec = -9e15*torch.ones_like(e)
attention = torch.where(adj > 0, e, zero_vec)
attention = F.softmax(attention, dim=1)
attention = F.dropout(attention, self.dropout, training=self.training)
h_prime = torch.matmul(attention, h)
if self.concat:
return F.elu(h_prime)
else:
return h_prime
[17]:
class GATLayer(nn.Module):
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
super(GATLayer, self).__init__()
self.dropout = dropout # drop prob = 0.6
self.in_features = in_features #
self.out_features = out_features #
self.alpha = alpha # LeakyReLU with negative input slope, alpha = 0.2
self.concat = concat # conacat = True for all layers except the output layer.
# Xavier Initialization of Weights
# Alternatively use weights_init to apply weights of choice
self.W = nn.Parameter(torch.zeros(size=(in_features, out_features)))
nn.init.xavier_uniform_(self.W.data, gain=1.414)
self.a = nn.Parameter(torch.zeros(size=(2*out_features, 1)))
nn.init.xavier_uniform_(self.a.data, gain=1.414)
# LeakyReLU
self.leakyrelu = nn.LeakyReLU(self.alpha)
def forward(self, input, adj):
# Linear Transformation
h = torch.mm(input, self.W) # matrix multiplication
N = h.size()[0]
print(N)
# Attention Mechanism
a_input = torch.cat([h.repeat(1, N).view(N * N, -1), h.repeat(N, 1)], dim=1).view(N, -1, 2 * self.out_features)
e = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(2))
# Masked Attention
zero_vec = -9e15*torch.ones_like(e)
attention = torch.where(adj > 0, e, zero_vec)
attention = F.softmax(attention, dim=1)
attention = F.dropout(attention, self.dropout, training=self.training)
h_prime = torch.matmul(attention, h)
if self.concat:
return F.elu(h_prime)
else:
return h_prime
Use it¶
[18]:
from torch_geometric.data import Data
from torch_geometric.nn import GATConv
from torch_geometric.datasets import Planetoid
import torch_geometric.transforms as T
import matplotlib.pyplot as plt
name_data = 'Cora'
dataset = Planetoid(root= '/tmp/' + name_data, name = name_data)
dataset.transform = T.NormalizeFeatures()
print(f"Number of Classes in {name_data}:", dataset.num_classes)
print(f"Number of Node Features in {name_data}:", dataset.num_node_features)
Number of Classes in Cora: 7
Number of Node Features in Cora: 1433
[19]:
class GAT(torch.nn.Module):
def __init__(self):
super(GAT, self).__init__()
self.hid = 8
self.in_head = 8
self.out_head = 1
self.conv1 = GATConv(dataset.num_features, self.hid, heads=self.in_head, dropout=0.6)
self.conv2 = GATConv(self.hid*self.in_head, dataset.num_classes, concat=False,
heads=self.out_head, dropout=0.6)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = F.dropout(x, p=0.6, training=self.training)
x = self.conv1(x, edge_index)
x = F.elu(x)
x = F.dropout(x, p=0.6, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = "cpu"
model = GAT().to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.005, weight_decay=5e-4)
model.train()
for epoch in range(1000):
model.train()
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
if epoch%200 == 0:
print(loss)
loss.backward()
optimizer.step()
tensor(1.9457, grad_fn=<NllLossBackward0>)
tensor(0.6872, grad_fn=<NllLossBackward0>)
tensor(0.6268, grad_fn=<NllLossBackward0>)
tensor(0.6055, grad_fn=<NllLossBackward0>)
tensor(0.5019, grad_fn=<NllLossBackward0>)
[20]:
model.eval()
_, pred = model(data).max(dim=1)
correct = float(pred[data.test_mask].eq(data.y[data.test_mask]).sum().item())
acc = correct / data.test_mask.sum().item()
print('Accuracy: {:.4f}'.format(acc))
Accuracy: 0.8110